Green
Can we train a high-accuracy vision model for waste sorting without a single real photo?
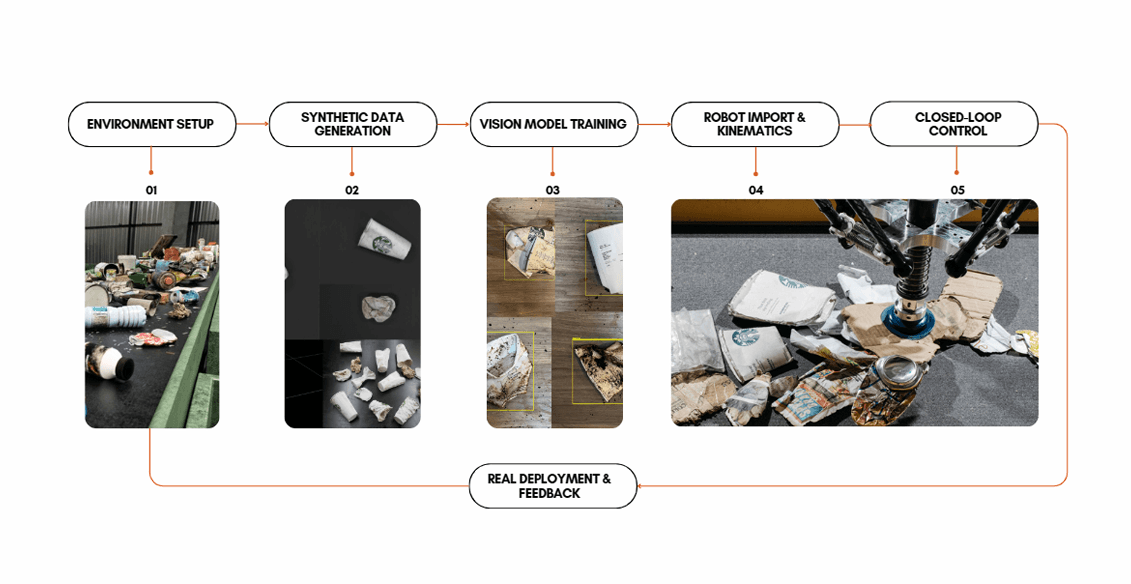
Synthetic data is rapidly becoming a game-changer in machine learning and vision-based AI. Companies across waste management, agriculture, and robotic automation often face high costs and time-consuming processes for data collection and annotation. At Silera, we set out to prove that photorealistic simulation can accelerate model training and reduce costs, all without collecting real-world photos.
Challenge: Waste Sorting Without Real-World Images
Sorting recyclable materials or trash typically demands thousands of labeled images. Gathering them involves messy manual setups, potential health risks, and expensive labeling overhead. Our goal was to demonstrate that even in complex waste environments, an AI vision model could learn purely from synthetic data, starting with a simple yet iconic target: the Starbucks cup.
In this pilot, we physically collected some used Starbucks cups, bent, stained, and crumpled, to serve as our real-world ‘nasty’ test set. We then built digital 3D models to match these shapes, created synthetic scenes, and wanted to see if our purely synthetic-trained model could handle the actual cups without extra real-data training.
Training Overview
Annotated Data Samples Model ~9k YoloV11m, YoloV11n + ~500 YoloV11m
Synthetic Training samples for the first batch of training
In the first iteration, we generated variations in texture/shape/dirt/spills on the Starbucks cup. 9k images were generated with perfect annotations.
Maintained the original Starbucks cup characteristics while adding the trashed components.

We gathered several used Starbucks cups, applying coffee stains and minor tears. These real cups became our final test set, about 100 images, captured with a phone camera under normal indoor lighting.
The goal: see if the model trained on synthetic variations alone could accurately detect and segment them.
The first set of training revealed ~0.99 mAP on the val set (synthetic) and good results on OOD real world samples.
mAP (mean Average Precision) is a standard metric to measure how well an object detector performs across multiple classes and thresholds. For context, a 0.995 mAP means near-perfect detection across our entire real test set, something typically difficult with no real training images.
However, the model was making clear misses on some OOD samples. For eg;

OOD (Out-of-Distribution) samples are real-world examples not seen during training, representing scenarios that differ from your synthetic data distribution.
These missed detections showed our synthetic dataset lacked certain trash variations or textures, so we generated additional specialized images to cover these exact failure modes. This time around with the intention of better segregation from rest of the trash.
Synthetic Training sample for iterative batch
The model missed a handful, so we created an additional 500 specialized synthetic images targeting those failure modes.

Further training improved the mAP to ~0.995 and resulted in better detections on the OOD samples (the ones that were missed before). Demonstrating that iterating synthetic data is both fast and cost-effective.


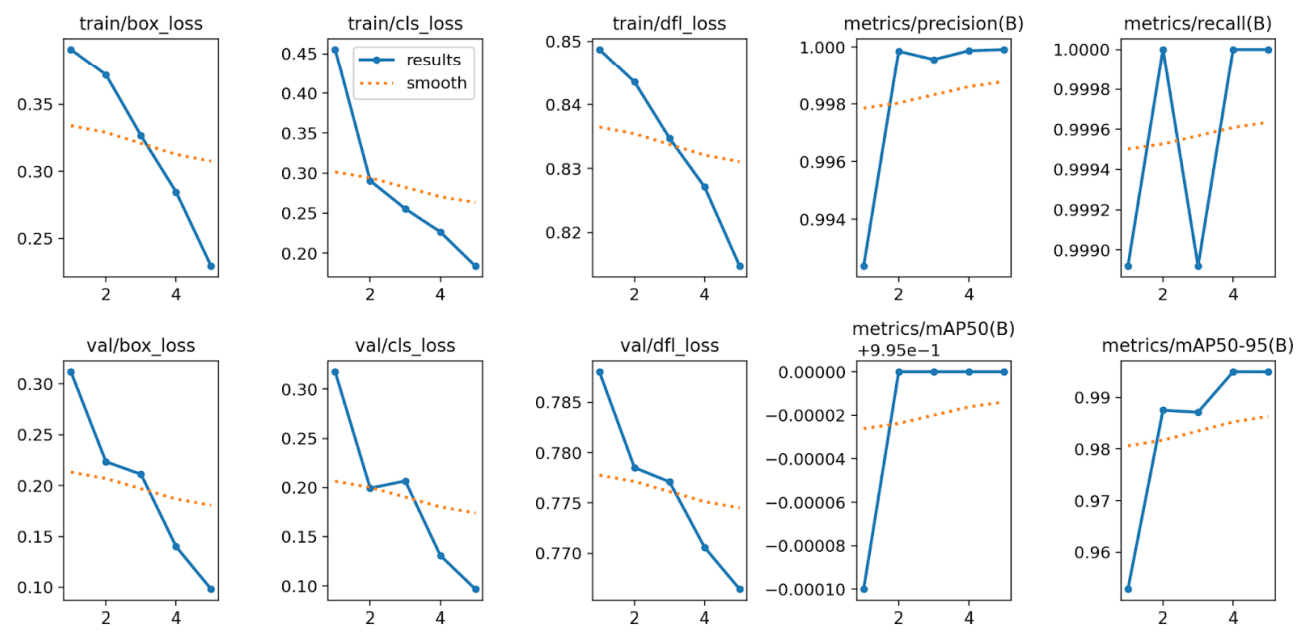
These graphs show our training (blue) and validation (orange) curves for box loss, classification loss, etc. The continuous drop indicates the model is learning effectively, while near 1.0 precision/recall suggests strong detection performance. The final ~0.995 mAP highlights near-perfect results on our synthetic+OOD test set.
Why This Matters for Multiple Industries
Our Starbucks cup pilot has implications for many sectors needing vision-based AI:
Waste Management & Recycling
Quickly generate synthetic scenarios for plastic bottles, aluminum cans, or complex packaging.
Reduce data-collection costs and speed up new model deployments.
Agriculture & Greenhouse Automation
Simulate early disease detection on plant leaves, with different lighting or growth stages.
Avoid physically collecting endless seasonal images.
Robotics & Automation
Any bin-picking or quality-inspection task benefits from robust synthetic data.
No disruption to production lines, no multi-week real data labeling.
Each iteration, where we identify misses on real samples and quickly generate targeted synthetic data, helps us converge faster on a robust model that truly handles real-world unpredictability.
This approach can be extended to any vision-based robotics use case.
Key Takeaways
This near-perfect performance on genuinely messy real cups is crucial. It shows synthetic data plus domain randomization can yield robust real-world AI models. Manufacturers, recycling plants, and other industries can drastically cut data-collection overhead while maintaining top-tier accuracy.
High Accuracy with Zero Real Photos
Achieving 0.995 mAP purely from synthetic scenes highlights how far photoreal rendering plus domain randomization can go.
Cost & Time Savings
Traditional collection might take weeks and cost tens of thousands in labeling. We did it in days, with automated annotations.
Scalable to Complex Scenarios
Once we have 3D models of an object, we can easily add new textures or new backgrounds. This approach is flexible for varied or messy tasks.
Each iteration helps us bridge the sim-to-real gap faster, so integrators can train AI models without incurring huge real-world data costs.
Interested in trying synthetic data for your vision-based AI? Contact us to see how quickly we can spin up photorealistic data for your specific challenge.